CleverMaps Shell is controlled solely by a set of predefined commands. These commands can be divided into 4 categories or workflow states. All commands and parameters are case-sensitive.
Each command can be further specified by parameters, which can have default values. Each parameter also has a "--" prefix, which is a technicality and is not mentioned in the tables below, for the sake of readability.
Parameters with string type take string input as a value if they are mentioned. Parameters with enum type have predefined enumeration of strings, which can be passed as a value. Parameters with boolean type can be passed either true, false or no value (=true).
Workflow states
-
Started - you have started the tool
-
Connected to server - you have successfully logged in to your account on a specific server
-
Opened project - you have opened a project you have access to
-
Opened dump - you have created dump, or opened an existing one
Started state
login
Log in as a user to CleverMaps with the correct credentials.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
OPTIONAL |
generated CleverMaps access token (see how to get one) |
stored in config file |
|
|
string |
OPTIONAL |
JWT token generated after signing with limited 1h validity |
|
|
|
string |
OPTIONAL |
directory where your dumps will be stored |
stored in config file |
|
|
string |
OPTIONAL |
server to connect to default = |
stored in config file |
|
|
string |
OPTIONAL |
proxy server hostname |
stored in config file |
|
|
integer |
OPTIONAL |
proxy server port |
stored in config file |
|
|
string |
OPTIONAL |
AWS S3 Access Key ID required for S3 upload (loadCsv --s3Uri) |
stored in config file |
|
|
string |
OPTIONAL |
AWS S3 Secret Access Key required for S3 upload (loadCsv --s3Uri) |
stored in config file |
setup
Store your config and credentials in a file so you don't have to specify them each time you log in.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
OPTIONAL |
generated CleverMaps access token (see how to get one) |
stored in config file |
|
|
string |
OPTIONAL |
server to connect to |
stored in config file |
|
|
string |
OPTIONAL |
directory where your dumps will be stored |
stored in config file |
|
|
string |
OPTIONAL |
proxy server hostname |
stored in config file |
|
|
integer |
OPTIONAL |
proxy server port |
stored in config file |
|
|
string |
OPTIONAL |
AWS S3 Access Key ID required for S3 upload (loadCsv --s3Uri) |
stored in config file |
|
|
string |
OPTIONAL |
AWS S3 Secret Access Key required for S3 upload (loadCsv --s3Uri) |
stored in config file |
Connected to server
openProject
Open a project and set it as current. Opens the dump if it exists.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
REQUIRED |
Project ID to be opened |
|
listProjects
List all projects available to you on the server.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
boolean |
OPTIONAL |
specifies if the output should be more verbose |
|
|
|
enum |
OPTIONAL |
list projects by share type |
|
|
|
string |
OPTIONAL |
list projects by organization (organization ID) |
|
createProject
Create a new project and open it.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
REQUIRED |
title of the project |
|
|
|
string |
OPTIONAL |
description of the project. A description can be formatted by markdown syntax. |
|
|
|
string |
OPTIONAL |
ID of the organization which will become the owner of the project |
|
cloneProject
Clones project from source and open it. Cloning is handled on the server, so no data or metadata is transferred to the local Shell environment.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
REQUIRED |
Project ID of the project from which new project will be cloned |
|
|
|
string |
REQUIRED |
ID of the organization which will become the owner of the project |
|
|
|
string |
OPTIONAL |
description of the project. A description can be formatted by markdown syntax. |
|
|
|
string |
OPTIONAL |
title of the project, if none provided defaults to = "Clone of [projectName]" |
|
editProject
Edit project properties.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
REQUIRED |
Project ID of project to be edited |
|
|
|
string |
OPTIONAL |
new title of the project |
|
|
|
string |
OPTIONAL |
new description of the project |
|
|
|
string |
OPTIONAL |
new status of the project |
|
|
|
string |
OPTIONAL |
new ID of the organization which will become the owner of the project |
|
deleteProject
Delete an existing project.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
REQUIRED |
Project ID of the project to be deleted |
|
Opened project
importProject
Allows you to import:
-
project from a server (e.g. a data dimension)
-
a local dump of a project
-
perform import on the server
You can also import a part of a project with one of the parameters (dashboards, datasets, indicators, indicatorDrills, markers, markerSelectors, metrics, views). If you specify none of these parameters, the whole project will be imported. Every time you specify a datasets parameter, corresponding data will be imported.
Before each import, validate command is called in the background. If there are any model validation violations in the source project, the import is stopped, unless you also provide the --force parameter.
During the import, the origin key is set to all metadata objects. This key indicates the original location of the object (server and the project). This has a special use in the case of datasets & data import. import first takes a look at what datasets currently are in the project and compares them with datasets that are about to be imported. Datasets that are not present in the destination project will be imported automatically. In the case of datasets that are present in the destination project, 3 cases might occur:
-
if they have the same name and origin, the dataset will not be imported
-
if they have the same name but different origin, a warning is shown and the dataset will not be imported
-
if a
prefixis specified, all source datasets will be imported
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
REQUIRED |
Project ID of the project from which files will be imported |
|
|
|
boolean |
VARIES |
import project from local dump |
|
|
|
boolean |
VARIES |
performs import of specified project on server |
|
|
|
string |
OPTIONAL |
cascade import object and all objects it references see usage examples below |
|
|
|
string |
OPTIONAL |
specify a prefix for the metadata objects and data files |
|
|
|
boolean |
OPTIONAL |
import dashboards only |
|
|
|
boolean |
OPTIONAL |
import data permission only |
|
|
|
boolean |
OPTIONAL |
import datasets only |
|
|
|
boolean |
OPTIONAL |
import exports only |
|
|
|
boolean |
OPTIONAL |
import indicators only |
|
|
|
boolean |
OPTIONAL |
import indicator drills only |
|
|
|
boolean |
OPTIONAL |
import markers only |
|
|
|
boolean |
OPTIONAL |
import marker selectors only |
|
|
|
boolean |
OPTIONAL |
import metrics only |
|
|
|
boolean |
OPTIONAL |
import project settings only |
|
|
|
boolean |
OPTIONAL |
import shares only |
|
|
|
boolean |
OPTIONAL |
import views only |
|
|
|
boolean |
OPTIONAL |
ignore source project skip failed dataset dumps (for projects with incomplete data) default = false |
|
|
|
boolean |
OPTIONAL |
skip data import default = false |
|
Usage examples:
Cascade import
// import all objects referenced from catchment_area_view including datasets & data
importProject --project djrt22megphul1a5 --cascadeFrom catchment_area_view
// import all objects referenced from catchment_area_view except including datasets & data
importProject --project djrt22megphul1a5 --cascadeFrom catchment_area_view --dashboards --exports --indicatorDrills --indicators --markerSelectors --markers --metrics --views
// import all objects referenced from catchment_area_dashboard
importProject --project djrt22megphul1a --cascadeFrom catchment_area_dashboard
// import all objects (datasets) referenced from baskets dataset - data model subset
importProject --project djrt22megphul1a5 --force --cascadeFrom baskets
importDatabase
Allows you to create datasets and import data from an external database.
This command reads the database metadata from which datasets are created, then imports the data and saves them as CSV files. You can choose to import either of which with --skipMetadata and --skipData parameters. Please note that this command does not create any metadata objects other than datasets. It's also possible to import only specific tables using the --tables parameter.
The database must be located on a running database server which is accessible under a URL. This can be on localhost, or anywhere on the internet. Valid credentials to the database are necessary.
So far, the command supports these database engines:
-
PostgreSQL (https://www.postgresql.org/)
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
enum |
REQUIRED |
name of the database engine |
[postgresql] |
|
|
string |
REQUIRED |
database server hostname for local databases, use |
|
|
|
integer |
REQUIRED |
database server port |
|
|
|
string |
OPTIONAL |
name of the database schema leave out if your engine does not support schemas, or the schema is |
|
|
|
string |
REQUIRED |
name of the database |
|
|
|
string |
REQUIRED |
user name for login to the database |
|
|
|
string |
REQUIRED |
user's password |
|
|
|
array |
OPTIONAL |
list of tables to import leave out if you want to import all tables from the database example = |
|
|
|
boolean |
OPTIONAL |
skip data import default = false |
|
|
|
boolean |
OPTIONAL |
skip metadata import default = false |
|
Usage examples:
importDatabase --engine postgresql --host localhost --port 5432 --database my_db --user postgres --password test
importDatabase --engine postgresql --host 172.16.254.1 --port 6543 --schema my_schema --database my_db --user postgres --password test --tables orders,clients,stores
loadCsv
Load data from a CSV file into a specified dataset.
loadCsv also offers various CSV input settings. Your CSV file may contain specific features, like custom quotes or separator characters. The parameters with the csv prefix allow you to configure the data load to fit these features, instead of transforming the CSV file to one specific format. Special cases include the csvNull and csvForceNull parameters.
-
csvNullallows you to specify a value, which will be interpreted as a null value-
e.g. "
false" or "_"
-
-
csvForceNullthen specifies on which columns the custom null replacement should be enforced-
e.g. "
name,title,description"
-
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
VARIES |
path to the CSV file |
|
|
|
string |
VARIES |
URI of an object on AWS S3 to upload (see examples below) |
|
|
|
string |
VARIES |
HTTPS URL which contains a CSV file to be loaded into the dataset |
|
|
|
string |
REQUIRED |
name of dataset into which the data should be loaded |
|
|
|
enum |
required |
data load mode
|
|
|
|
boolean |
OPTIONAL |
specifies if the CSV file to upload has a header default = |
|
|
|
char |
OPTIONAL |
specifies the CSV column separator character default = |
|
|
|
char |
OPTIONAL |
specifies the CSV quote character default = |
|
|
|
char |
OPTIONAL |
specifies the CSV escape character default = |
|
|
|
string |
OPTIONAL |
specifies the replacement of custom CSV null values |
|
|
|
enum |
OPTIONAL |
specifies which CSV columns should enforce the null replacement |
|
|
|
boolean |
OPTIONAL |
enables more verbose output default = |
|
|
|
boolean |
OPTIONAL |
enables multipart file upload (recommended for files larger than 2 GB) default = false |
|
|
|
boolean |
OPTIONAL |
enables gzip compression default = true |
|
|
|
boolean |
OPTIONAL |
disables refreshing of materialized view when loading dimension linked (see automatic area mapper) default = false |
|
Usage examples:
Please note that your AWS S3 Access Key ID and Secret Access Key must be set using setup command first.
Load CSV from AWS S3
loadCsv --dataset orders --mode full --s3Uri s3://my-company/data/orders.csv --verbose
Load CSV from HTTPS URL
loadCsv --dataset orders --mode full --url http://www.example.com/download/orders.csv --verbose
dumpCsv
Dump data from a specified dataset into a CSV file.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
REQUIRED |
name of the dataset do dump |
|
|
|
boolean |
OPTIONAL |
overwrites dumped data |
|
dumpProject
Dump project data and metadata to a directory. If the dump is successful, the current dump is opened.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
boolean |
OPTIONAL |
skip metadata dump default = false |
|
|
|
boolean |
OPTIONAL |
skip data dump default = false |
|
|
|
boolean |
OPTIONAL |
overwrites current dump default = false |
|
|
|
boolean |
OPTIONAL |
import only native datasets (without origin attribute) default = false |
|
|
|
boolean |
OPTIONAL |
skip failed dataset dumps (for projects with incomplete data) default = false |
|
openDump
Open dump of project.
This command has no parameters.
truncateProject
Deletes all metadata and data from the project.
This command has no parameters.
validate
Validate the project's data model and data integrity. An update of dataset definition (metadata) should be followed by a data update. Typically, it helps to make a full data load for an updated dataset (see loadCsv command). During the full load, an original DWH table is dropped and data is loaded into a new table regarding the updated dataset definition.
If a user updates just a metadata model, it can cause an inconsistency between the metadata model and the DWH database model. The validate command is used to detect these problems.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
OPTIONAL |
project ID of other project which will be validated |
|
|
|
string |
OPTIONAL |
skip validations of the data model. Model validation compares a metadata definition of dataset with a table definition in DWH database (DDL). This validation is fast, no data are validated. default = false |
|
|
|
string |
OPTIONAL |
skip validations of the data itself default = false |
|
List of violation types:
|
validation category |
violation |
violation description |
|---|---|---|
|
model |
MissingTableValidationException |
missing table in DWH database for given dataset |
|
model |
MissingColumnValidationException |
missing column in DWH table that is present in dataset definition |
|
model |
NotMatchingDataTypeColumnException |
data type of a columns in DWH tables differs from a type in dataset definition |
|
model |
MisorderColumnValidationException |
order of columns in DWH table does not match order of properties in dataset definition |
|
model |
MissingPrimaryKeyColumnValidationException |
primary key defined in dataset definition was not found in DWH table |
|
model |
UnexpectedColumnValidationException |
an extra column was found in DWH table compared with the dataset definition |
|
model |
MismatchingForeignKeyDataTypeException |
a foreign key column data type must be the same as a data type of referenced primary key |
|
data |
NotUniquePrimaryKeyValidationException |
duplicated values has been found in a primary key column |
|
data |
NanInNumericColumnValidationException |
NaN value has been found in a numeric column |
|
data |
ReferenceIntegrityValidationException |
compares foreign key values with a referenced values of a primary key column. Missing values are reported. |
Opened dump
addMetadata
Add a new metadata object and upload it to the project. The file must be located in a currently opened dump, and in the correct directory.
If the --objectName parameter is not specified, addMetadata will add all new objects in the current dump.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
OPTIONAL |
name of the object (with or without .json extension) |
|
Updating existing metadata objects
When modifying already added (uploaded) metadata objects use pushProject command for uploading modified objects to the project.
createMetadata
Create a new metadata object.
At this moment, only dataset type is supported. Datasets are generated from a provided CSV file.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
enum |
REQUIRED |
type of the object to create |
|
|
|
string |
REQUIRED |
name of the object to create |
|
|
|
enum |
VARIES |
name of the object copy (with or without .json extension) required only for |
|
|
|
string |
VARIES |
path to the CSV file (located either in dump, or anywhere in the file system) required only for |
|
|
|
string |
VARIES |
name of the CSV column that will be marked as primary key required only for |
|
|
|
string |
VARIES |
name of the required only for |
|
|
|
char |
OPTIONAL |
specifies the CSV column separator character default = |
|
|
|
char |
OPTIONAL |
specifies the CSV quote character default = |
|
|
|
char |
OPTIONAL |
specifies CSV escape character default = |
|
Usage examples:
createMetadata --type dataset --subtype basic --objectName "baskets" --file "baskets.csv" --primaryKey "basket_id"
createMetadata --type dataset --subtype geometryPoint --objectName "shops" --file "shops.csv" --primaryKey "shop_id"
createMetadata --type dataset --subtype geometryPolygon --objectName "district" --geometry "districtgeojson" --file "district.csv" --primaryKey "district_code"
removeMetadata
Remove a metadata object from the project and from the dump. The file must be located in a currently opened dump, and must not be new.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
VARIES |
name of the object (with or without .json extension) |
|
|
|
string |
VARIES |
ID of the object |
|
|
|
boolean |
VARIES |
prints a sequence of orphan object is an object not referenced from any of the project's views, or visible anywhere else in the app |
|
renameMetadata
Rename a metadata object in a local dump and on the server. If the object is referenced in some other objects by URI (/rest/projects/$projectId/md/{objectType}?name=), the references will be renamed as well.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
REQUIRED |
current name of the object (with or without .json extension) |
|
|
|
string |
REQUIRED |
new name of the object (with or without .json extension) |
|
copyMetadata
Create a copy of an object existing in a currently opened dump.
This command unwraps the object from a wrapper, renames it and removes generated common syntax keys. If the objectName and newName arguments are the same, the object is unwrapped only.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
REQUIRED |
current name of the object (with or without .json extension) |
|
|
|
string |
REQUIRED |
name of the object copy (with or without .json extension) |
|
restoreMetadata
Restore metadata objects from a local dump onto the server.
If the --objectName parameter is not specified, restoreMetadata will restore, add and push all changed objects in the dump.
For objects present on the server and not in the local dump, restoreMetadata prints a list of removeMetadata commands to delete server objects.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
OPTIONAL |
name of the object (with or without .json extension) |
|
pushProject
Upload all modified files (data & metadata) to the project.
This command basically wraps the functionality of loadCsv. It collects all modified metadata to upload and performs a full load of CSV files.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
boolean |
OPTIONAL |
skip metadata push default = false |
|
|
|
boolean |
OPTIONAL |
skip data push default = false |
|
|
|
boolean |
OPTIONAL |
skip the run of default = false |
|
|
|
boolean |
OPTIONAL |
enables more verbose output default = false |
|
|
|
boolean |
OPTIONAL |
enables multipart file upload (recommended for files larger than 2 GB) default = false |
|
|
|
boolean |
OPTIONAL |
enables gzip compression default = true |
|
status
Check the status of a currently opened dump against the project on the server.
This command detects files which have been locally or remotely changed, are missing in a dump, and also detects files which have a syntax error or constraint violations.
When --remote is used, the command only displays metadata content on the server.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
boolean |
OPTIONAL |
list metadata content on the server default = false |
|
fetch
Fetch objects that have changed on the server and update local objects.
Server objects are compared with local objects, and the following action can happen:
-
an object changed on the server and not locally modified is dumped
-
an object changed on the server and locally modified creates conflict (see conflict)
-
an object deleted on the server and not locally modified is deleted
-
an object deleted on the server and locally modified is unwrapped and can be added again with
addMetadata
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
OPTIONAL |
name of the object to fetch (with or without .json extension) |
|
|
|
boolean |
OPTIONAL |
overwrite local changes |
|
Conflict
A conflict occurs when an object is modified on the server and locally. Conflicts are written to metadata objects and have to be resolved.
Conflict example:
...
"visualizations": {
<<<<<<< local
"grid": false
=============
"grid": true
>>>>>>> server
},
...
applyDiff
Create and apply metadata diff between two live projects.
This command compares all metadata objects of the currently opened project and the project specified in the --sourceProject command and applies changes to the currently opened dump. Metadata objects in the dump can be either:
-
added (completely new objects that aren't present in the currently opened project)
-
modified
-
deleted (deleted objects not present in the
sourceProject)
When the command finishes, you can review the changes applied to the dump using either status or diff commands. The command then tells you to perform specific subsequent steps. This can be one of (or all) these commands:
-
addMetadata(to add the new objects) -
pushProject(to push the changes in modified objects) -
removeMetadata(to remove the deleted objects - a command list which must be copypasted to Shell is generated)
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
required |
Project ID of the source project |
|
|
|
array |
OPTIONAL |
list of object types to be compared example = |
|
diff
Compare local metadata objects with those in the project line by line.
If the --objectName parameter is not specified, all wrapped modified objects are compared.
|
Parameter name |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
OPTIONAL |
name of a single object to compare (with or without .json extension) |
|
The command outputs sets of changes - "deltas" done in each object. Each object can have multiple deltas, which are followed by a header with the syntax:
/{objectType}/{objectName}.json
[ A1 A2 | B1 B2 ]
...
Where:
A1 = start delta line number in the dump file
A2 = end delta line number in the dump file
B1 = start delta line number in the remote file
B2 = end delta line number in the remote file
Specific output example:
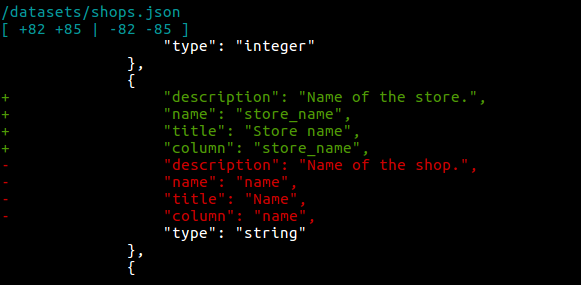
This means lines 82-85 in the dump object have been added (+) in favour of lines 82-85, which have been removed (−) from the remote object.