Double counting is a common issue in database design. When joining several incorrectly linked tables, some records may be duplicated and counted more than once. There are several cases which might cause double counting, and there's no uniform or automatic solution to these cases.
Double counting issues might happen to you during the development of projects on the platform. We've added a warning mechanism that will inform you when there's a risk of double counting. Let's have a look at some possible cases that might cause this error.
Example data model

The data model can be viewed in the application by hovering the Account icon on the bottom left of the Project page, and selecting Data model.
Incorrectly linked dataset
One of the most often cases of double counting is an incorrectly linked dataset. Say we have following data model, and we've just linked it to a demography dataset, which is aggregated on the postcode level.
The postcode dataset has a postcode foreign key that points to the demography_postcode dataset's primary key - id.
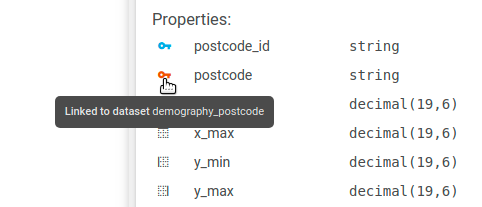
We have an existing view with usual metrics like turnover value, or number of clients. We will add a metric that computes the number of residents living in a selected area. We have a corresponding indicator which is included in the view's dashboard.
Residents metric syntax
{
"name": "residents_metric",
"type": "metric",
"content": {
"type": "function_sum",
"content": [
{
"type": "property",
"value": "demography_postcode.res_all"
}
]
}
}
With no administrative unit selected, the metric result is correct:

But after drilling on an administrative unit, e.g., a district, the value changes drastically and a warning sign appears.
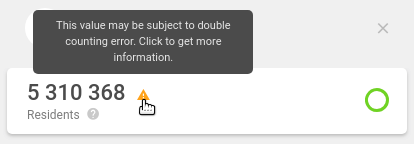
In this query, the dwh query service joins in the baskets and clients datasets, which do not relate 1:1 to the demograhy_postcode dataset. This causes some rows from the demograhy_postcode dataset to be counted in more than once, and the resulting sum is much higher.
The solution is to switch the foreign key reference to point the other way. So, we will set the demography_postcode.postcode_id to point to the postcode dataset, the fixed model will look like this:

And the metric result is correct, after drilling on the same administrative unit.

Incorrect metric
The other possible way to induce double counting is to write a metric that joins in additional datasets which do not have a 1:1 relation.
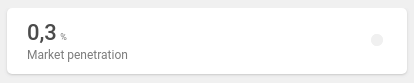
Based on the example data model, let's add a market penetration metric. This metric is a simple fraction - the numerator is a count of clients, and the denominator is a sum of all households.
Market penetration metric syntax
{
"name": "market_penetration_metric",
"type": "metric",
"content": {
"type": "function_divide",
"content": [
{
"type": "function_count",
"content": [
{
"type": "property",
"value": "clients.client_id"
}
]
},
{
"type": "function_sum",
"content": [
{
"type": "property",
"value": "demography_postcode.households"
}
]
}
]
}
}
The metric result is a percentage, and you can see the double counting warning sign.

In this case, the metric result is wrong because of the filters in the view, which join in the baskets dataset.
The clients dataset has a 1:n relation to the baskets dataset - the usual client has shopped more than once at our stores. So by joining in the baskets dataset, we multiply our clients by the number of all their baskets.
To fix this issue, we need to change the metric so it doesn't count in these filters - use the withoutFilters option.
Market penetration metric syntax
{
"name": "market_penetration_metric",
"type": "metric",
"content": {
"type": "function_divide",
"content": [
{
"type": "function_count",
"content": [
{
"type": "property",
"value": "clients.client_id"
}
]
},
{
"type": "function_sum",
"content": [
{
"type": "property",
"value": "demography_postcode.households"
}
],
"options": {
"withoutFilters": [
"baskets.*"
]
}
}
]
}
}
The metric result is now correct, and the double counting warning has disappeared.
If you don't think you see your case listed here, contact us at support@clevermaps.io. Please note that your issue might not be 100% identical to the solutions described here, the solution lies in the principle of your data model design.